Optimal land cover sampling

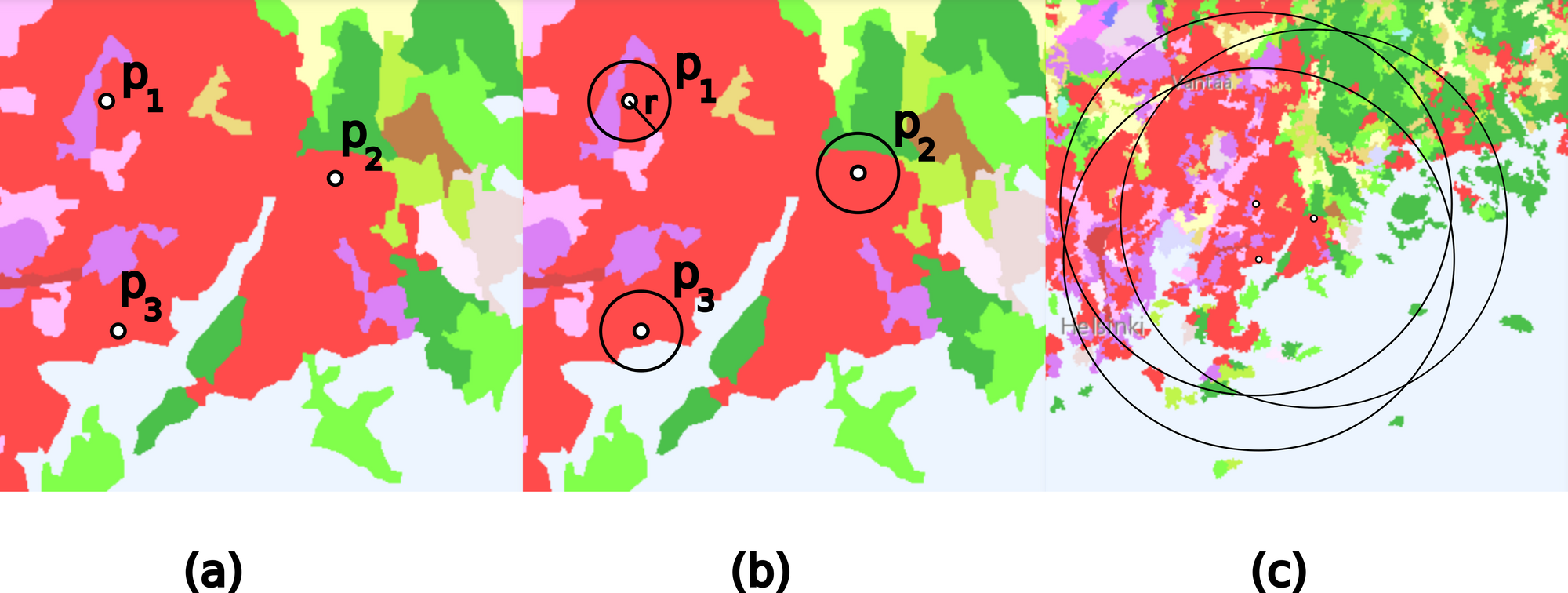
Land cover is defined as the physical material at the surface of Earth. Different types of land cover classes include for example grass, asphalt, trees, bare ground and water. Information on land cover is usually captured using field surveys and analysis of remotely sensed imagery.
Land cover sampling is a process where land cover information is extracted from a land cover dataset around predefined geographical sample points. The size of the sampling neighborhood is determined by the sampling radius, which has an effect on the resulting land cover characterization of the points. In a recent article draft we describe a method for optimally sampling land cover data around the sample points (click below to download the article draft).
The general idea is to maximize the information obtained by land cover sampling, by adjusting the size of the sampling radius around the sample points. The method is primarily motivated by characterizing the human habitats in medical cohort studies (HEDIMED, www.hedimed.eu). However, the proposed sampling method can be used in any sampling problem with n-dimensional spatial data and a countable number of classes.
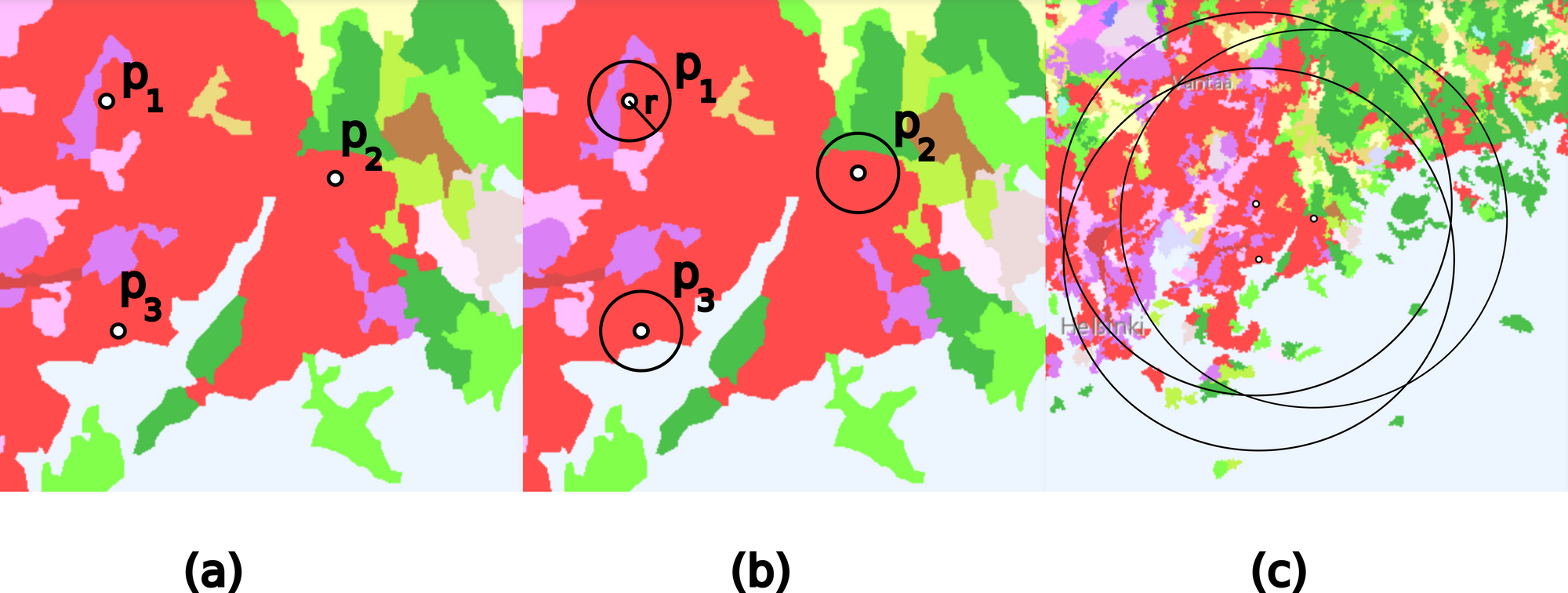
Initial numerical experiments performed on CORINE land cover data and random locations in built-up areas suggest that the sampling radius has a significant effect on the land cover characterization of the locations. The optimal sampling radius is found by studying the spread of land cover in sampling areas of different sizes.
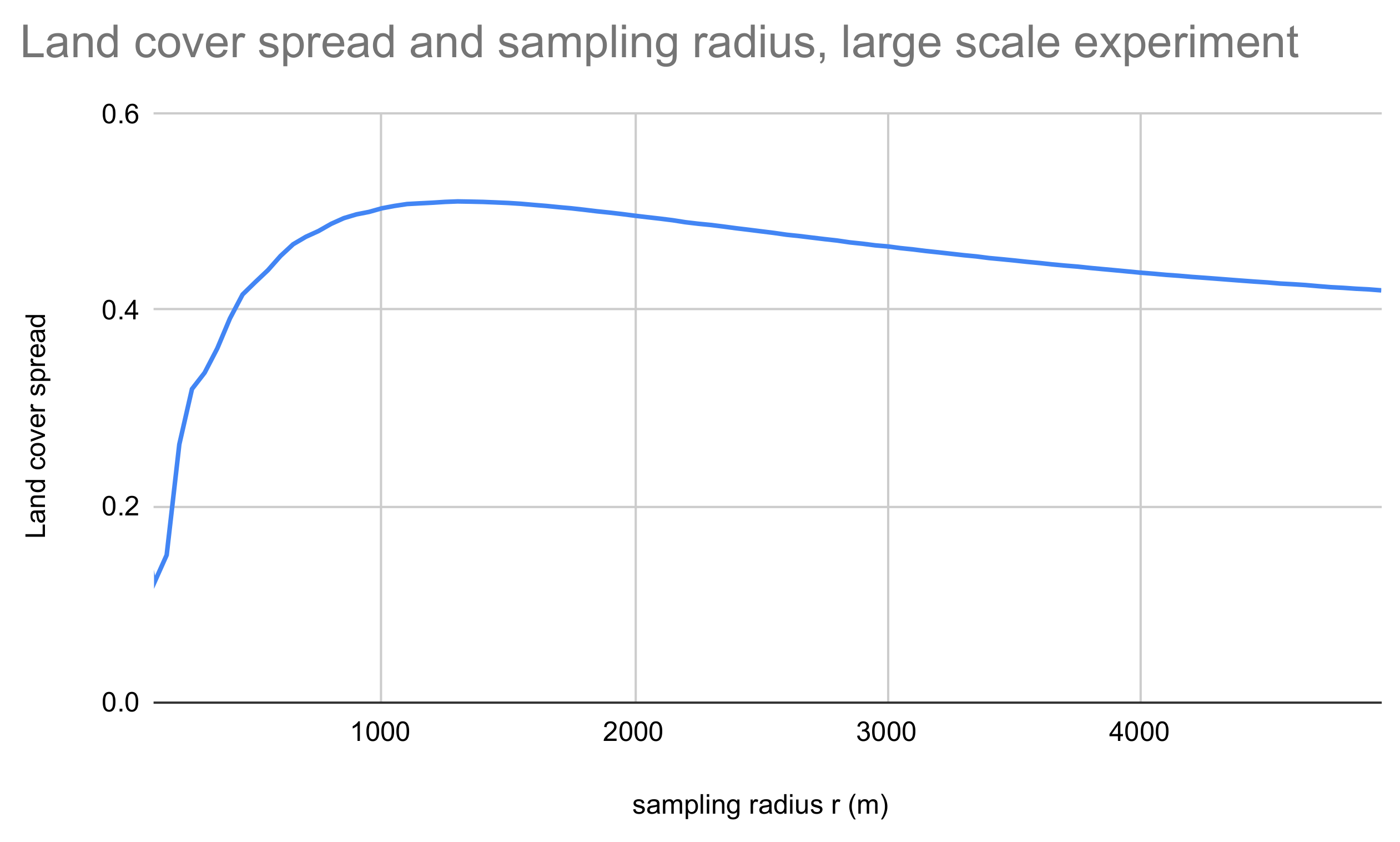
In the initial experiments, the optimal sampling radius for CORINE land cover data is found at around 1.3 kilometers for random points in built-up areas. However, both the land cover data as well as the sampling point data set have an effect on the size of the optimal sampling area. The method proposed in this paper is easily implemented for any data sets and enables the sampling radius to be determined in a well-justified manner in all cases.
Download article draft: