PostGIS and why we like it
A short introduction of PostGIS and why we chose it for storing our vector data. A case study of ST_Simplify.
This blog post starts with a short introduction of PostGIS and why we chose it for storing our vector data. After that is a case study of ST_Simplify, a function of PostGIS.
Choosing a database for geospatial data
When we were comparing the different database solutions in the early days of Terramonitor for storing vector data, our final contenders could be grouped as
- a NoSQL solution such as AWS DynamoDB or MongoDB for a dynamic schema and large-scale distribution by design
- an SQL solution such as Postgres, MySQL, even some custom SQLite implementation for proven performance and reliability
The trend was from "too strict" SQL toward the lighter and leaner NoSQL, SQLite being a middle ground solution (but most likely a pain to manage in large scale). Then we found the PostGIS extension for Postgres, and the competition was over.
PostGIS
PostGIS is an open source Postgres extension designed for managing geospatial data. Fundamentally, it is about the datatypes geometry and geography used for storing polygon data, and operations for those. These operations include the obviously useful intersection, CRS transformation and area calculation. MongoDB has some geospatial query features, but nowhere close to the extent of PostGIS.
Number of vertices in a polygon
The first polygons we created in the database were hand drawn with a reasonable amount of vertices, generally less than 10. We then added data from external official sources, such as property border databases. These had units with up to hundreds of vertices per polygon. Still, this caused no practical problems in query complexity. After we got the first sources providing polygons created by sensors and automated analysis processes, the vertice count climbed to thousands, and even tens of thousands per polygon in the worst case. This started to cause practical problems.
Let's next take a look at one approach to solving those problems.
ST_Simplify
ST_Simplify is one of the numerous geospatial data handling functions provided by PostGIS. It is a good example of a feature you have at your disposal before you even realise you need it, all thanks to a lucky technological choice made before. It is a function for simplifying geometries using the Douglas-Pecker algorithm. It attempts to remove vertices from a polygon given a maximum tolerance, thus simplifying it. The larger the tolerance, the more aggressive the function will perform.
ST_Simplify: Case study
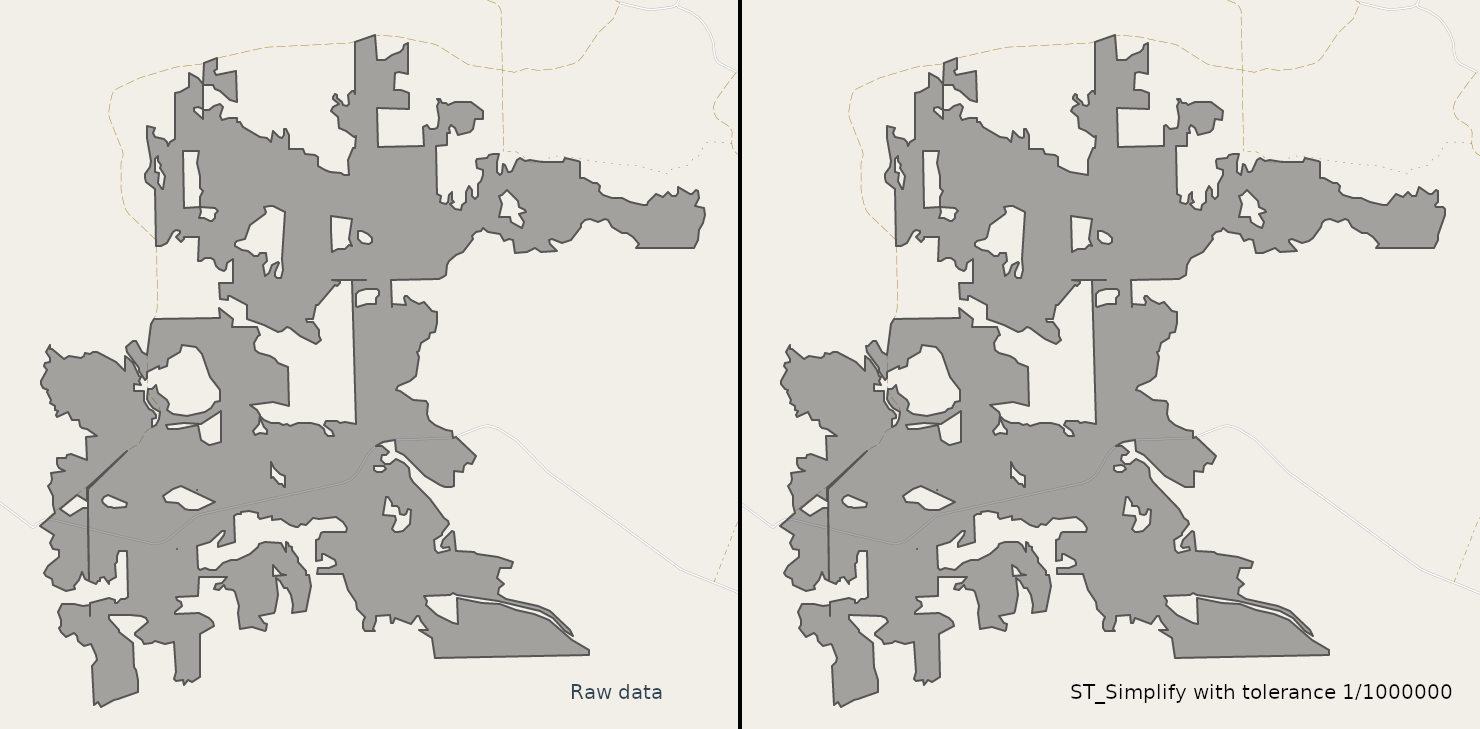
Figure 1 shows a side by side comparison of one of our larger polygons in our database on the left, and a polygon with ST_Simplify applied to it with a modest tolerance on the right.
The raw data has 5128 vertices spanning an area of 915.378 hectares, and taking about 183 kilobytes of space in GeoJSON format
The simplified version is produced with a tolerance of 10-6. The resulting polygon has 4211 vertices spanning 915.380 hectares, and taking about 103 kilobytes of space in GeoJSON format.
There is a difference of 20 square meters (0.0002%) after removing almost one fifth of the vertices (18%). Practically no difference in visual inspection. In some cases every square meter counts, of course, but in most cases simplification with this tolerance is completely acceptable.
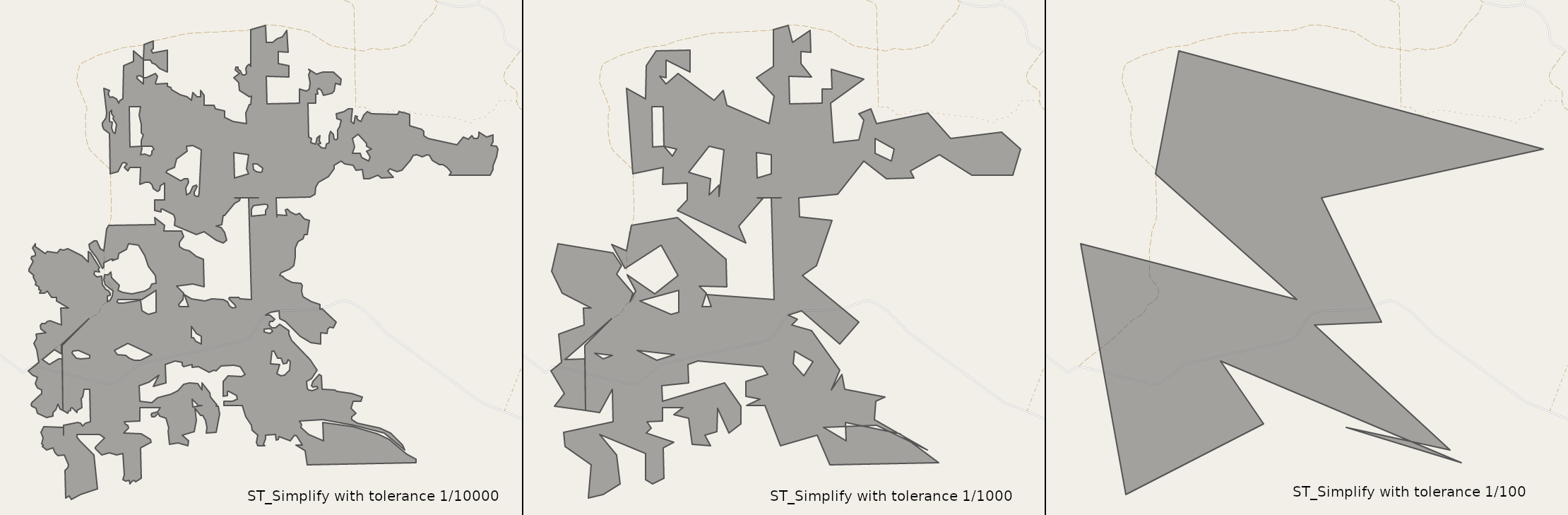
Figure 2 shows ST_Simplify with tolerance parameters of 10-4, 10-3, and 10-2. The number of vertices goes from 964 to 225, and all the way down to 15. The areas of the polygons are 915.788, 927.150 and 951.628 (hectares), while GeoJSON file sizes go from 35 kilobytes to 8 kilobytes, down to less than a kilobyte in the extreme (leftmost) case.
Using even as little as 964 vertices provides an adequately accurate result, with an area error of less than half a hectare (0.04%).
The middle polygon in Figure 2 shows an obvious approximation of the original polygon, an area error of 29%. A fair result with less than 5% of the original vertices, though! Going down to 15 vertices shows a result that is unacceptably inaccurate for most use cases.
Summary
So far, there have been absolutely no problems or restrictions on what we can do due to choosing Postgres and PostGIS as our database engine for storing geospatial data. On the contrary, it has provided us with more than we thought we would need, for instance ST_Simplify shown above. Unless you are working with data where details are paramount, ST_Simplify can be used to cut down 20 to 50 percent of your storage costs and operation complexity.